
糖尿病の予備軍(=糖尿病リスクの高い人)の段階でも,既に複数のクラスターに分かれているのかどうかを調べた結果が,ドイツのWagner論文として報告されています. 今月のNatureに掲載された最新の論文です.
この報告では,糖尿病予備軍の人を対象に,詳細な検査を行って Data-Driven Cluster分析してみたところ,既にこの段階で6つのグループ(クラスター)に分かれていることが判明しました.
複製検証
Data-Driven Cluster分析とは聞きなれない言葉ですが,最近は ビッグデータの解析手法として 広く行われつつあります. たとえば,Amazon は,延べ数十億人分の,『誰がいつどんなものをどういう順番で購入したか』などという膨大な顧客データを持っています. これをタイプ別に分析すれば,顧客の消費性向に応じて 適切な広告・在庫により 更に売り上げ増加が見込めます. ここで 使われているのがCluster分析です.ですから,Cluster分析は いまやビジネス用語として使われることの方が多いでしょう.
しかし,Data-Driven Cluster分析には弱点もあります.Data-Driven Cluster分析とは名前の通り『Dataまかせの分析』なので,系統的なCluster分析[★]と異なり,分析結果が偶然なのか必然なのかを判定する術がないのです. 極端な場合は,再計算するたびに全然違う結果になったりします. しかもあるデータベースでは,一見きれいにグループ分けできたように見えても,別のデータを持ってくるとまるで結果が違うこともあります. この場合 どちらかが正しいのか,あるいはどちらも間違っているのかすらわかりません.
[★]系統的なCluster分析:
上述の Amazonの顧客データの例では,たとえば顧客を年齢・性別・居住地・職業など,明確な分類基準を定めて グループ分けしていく方法です.これまでのマーケティングでは,この方法がオーソドックスなものでした.
そこで Data-Driven Cluster分析では,1つのデータベースではなく,複数のデータベースを素材にして,同じ結果がでるかどうか[=複製検証;Replication]を必ず行います.Wagner論文でも,もちろんこれを行っています.
複製結果
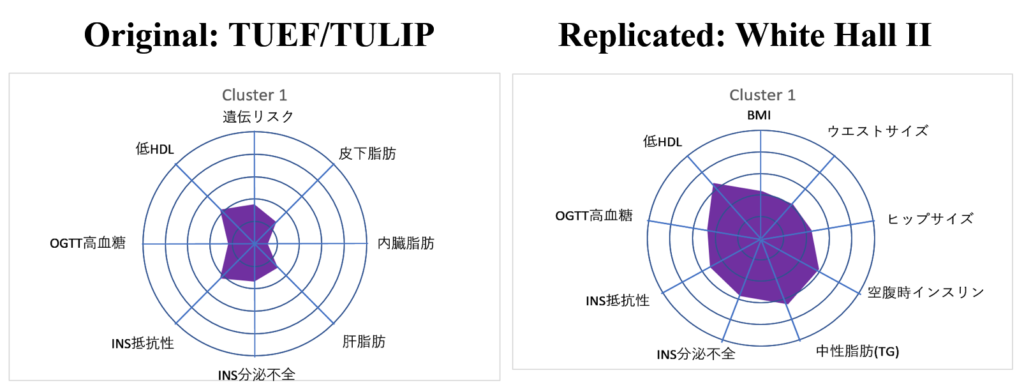
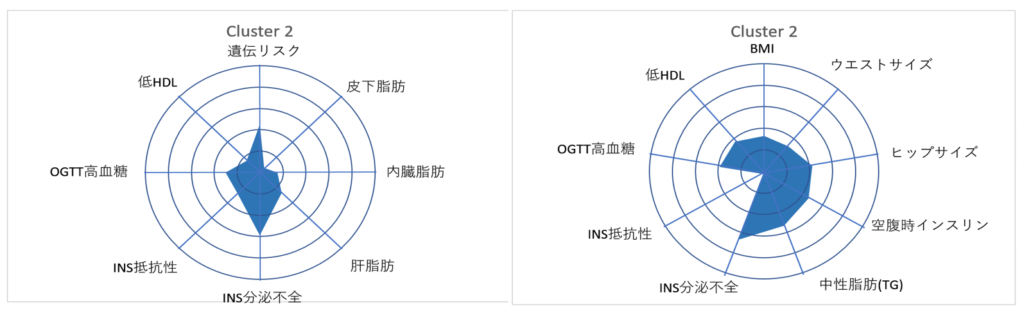
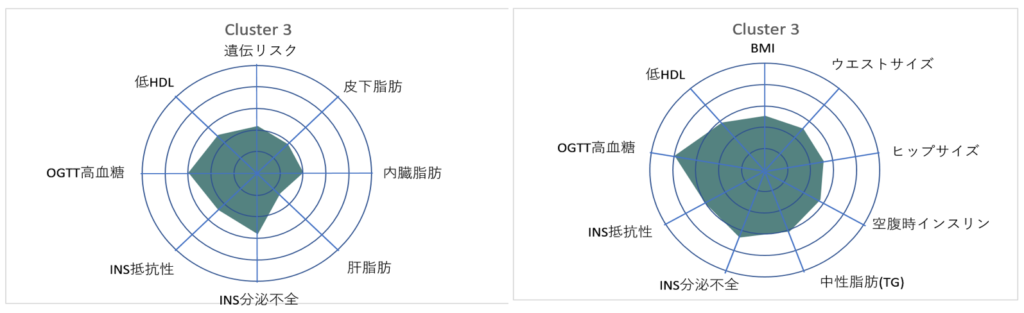
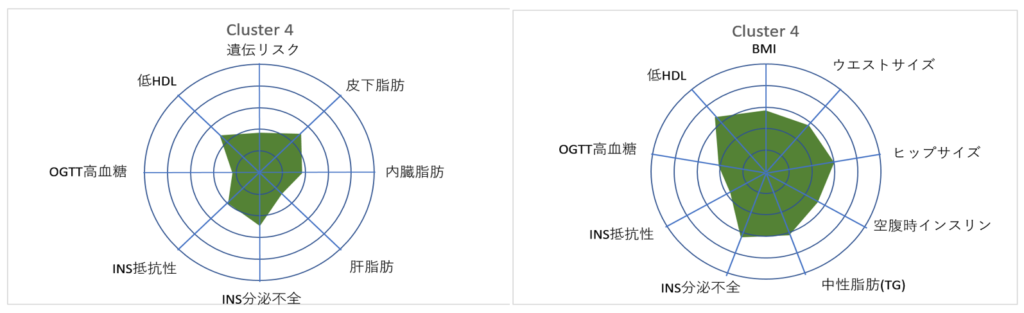
元のドイツの データベース【左;TUEF/TULIP】と,複製検証を行った英国のデータベース【右;WhiteHall II】のクラスター分析の結果は,以下の通りでした.
レーダーチャートで,塗りつぶし面積の大きいクラスターほど 糖尿病リスクが高いことを表しています.
これは厳密には複製検証になっていません.左と右で,パラーメータの数(左は8個,右は9個)が異なるし,本来まったく同じパラーメータを用いなければ 複製検証の意味がないのに,左右で一致していないパラーメータが半分以上あります.
もちろん Wagner論文の著者もそこはよくわかっています. しかし,まだ糖尿病とも診断されていない,つまり医学的には『正常』とされている人について,詳細な糖尿病・メタボ関連の検査を行って長期間追跡するなどというデータは 世界広しと言えども そうそう転がっていないのです. つまり,オリジナルのドイツのTUEF/TULIPデータベースと瓜二つのデータは存在しなかったのでしょう. やむなく,それに近いことを追跡調査している 英国の公務員健康状態追跡データベースで複製検証したと思われます.
通常であれば,これは 完全な複製検証とは言えないので,査読で却下されてもおかしくはありません. ところが 査読をパスして 堂々とNatureに掲載されました. それは この論文が,複製検証の不完全さを補って余りある,重大な発見・意義が認められたからだと思います.
なぜなら,これほど 条件が異なるにもかかわらず,6つのクラスターが左右双方で 対応した類似性がみられるからです.
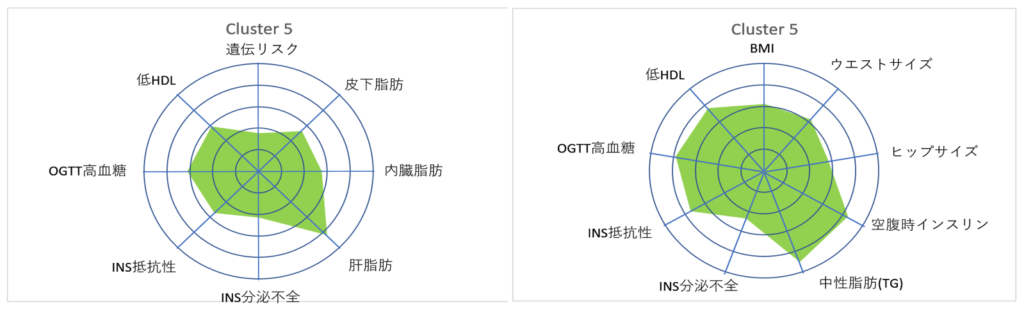
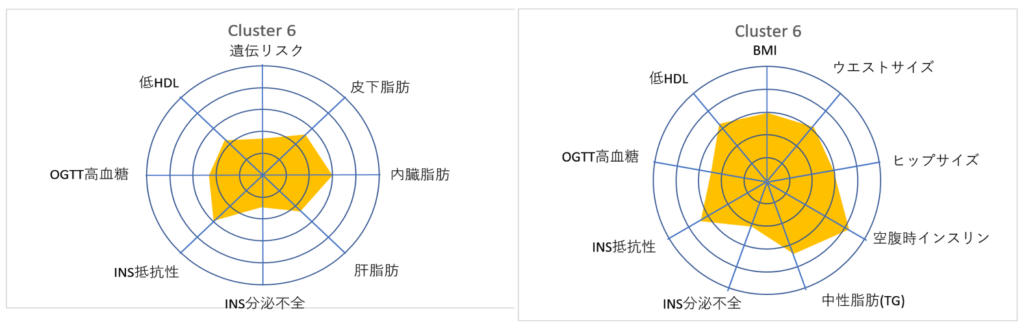
Cluster 6
Cluster 6は,肥満でインスリン抵抗性が高いです.これは Cluster5と同じです.ところが 糖負荷試験(OGTT)中の血糖値上昇は,むしろ Cluster6の方が優秀なのです. この特徴は左右で一致しています.
Cluster 5
Cluster5は,非常に強いインスリン抵抗性と肥満,そして 高血糖であり,ほぼ肥満型糖尿病の特徴をすべて備えています.これも 左右の複製で再現されています.
Cluster 4
Cluster4は肥満であるということを除いて,どこを見ても健康そのものです.内臓脂肪・肝脂肪が少なく,したがって OGTTの成績は優秀です.いわゆる『Healthy Fats[健康な肥満]』タイプです.
Cluster 3
Cluster 3は Cluster 5の正反対です. 内臓脂肪・肝脂肪は少なく,インスリン抵抗性はみられません.それにもかかわらず,OGTTで高血糖なのは,インスリンの絶対分泌能力が不足しているからです.これも左右で 特徴が一致しています.
Cluster 2
Cluster 2は,どこから見ても健康な人です.肥満も内臓脂肪もインスリン抵抗性もありません.
Cluster 1
Cluster 1だけは,オリジナル(=ドイツの TUEF/TULIP)を複製(=英国のWhiteHall II)でうまく複製検証できていないように見えます.どちらも全般的に特徴があやふやなので,明確なClusterを形成していないのではないかと思われます.
まるで違うのに
この連載の No.2の記事 で紹介しましたように,
ドイツの TUEF/TULIPは,どう見ても 糖尿病のリスクが高そうな人,すなわち糖尿病家系で, (欧米白人の糖尿病とはイコール肥満ですから)肥満の人だけの追跡データでした.
一方 複製検証に用いた 英国の WhiteHall IIは,ロンドンの中央官庁に勤務する33-55歳のすべての 白人公務員のデータです. つまり 特に糖尿病リスクが高い人だけを選別したのではありません. 体格でも選別していませんから,肥満の人もそうでない人もすべて含めています.
つまり,ドイツと英国のデータベースは,そのデータの構成がまるで違うのです. それにもかかわらず,6つのクラスターの特徴がよく一致しています.
このことから結論は一つです.
まだ糖尿病と診断されていない人でも,既に 将来の糖尿病リスクに関しては6つのパターンが存在する.
この考えに普遍性があることは証明されたと思います.
[7]に続く

コメント