話題のOpenAIによる文字起し「Whisper」を試してみました。
その備忘録です。

Whisperで動画から日本語の文字起しをする方法
作業環境は以下の通りです。
- M1 Mackbook Air
Windowsでも可能ですが、Pythonなので導入が簡単なMacで試しました。
Pythonのインストール
まずはPython3がインストールされている環境を用意します。
ターミナルを起動して
Homebrewを導入。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
Pythonをインストールしましょう。
brew install python3
ここら辺は「Mac Pythonインストール」で検索するとたくさんやり方がでています。
Whisperのインストール
いよいよ、本題です。
まずはユーザー>ユーザー名の直下にWhisperというフォルダを作成して、ディレクトリを指定しましょう。
ターミナルで以下のコマンドを叩きます。
mkdir whisper
cd whisperつづいてWhisperをインストールします。
下記のコマンドをターミナルで叩きましょう。
pip install git+https://github.com/openai/whisper.git最後に動画を読み込むためにffmpegのインストールもしましょう。
brew install ffmpeg環境構築は以上です。
動画の文字起しを実行
文字を起ししたい動画をWhisperフォルダに入れます。
今回はひろゆきさんの切り抜き動画で試してみました。

動画を格納しましたら、以下のコマンドを叩きます。
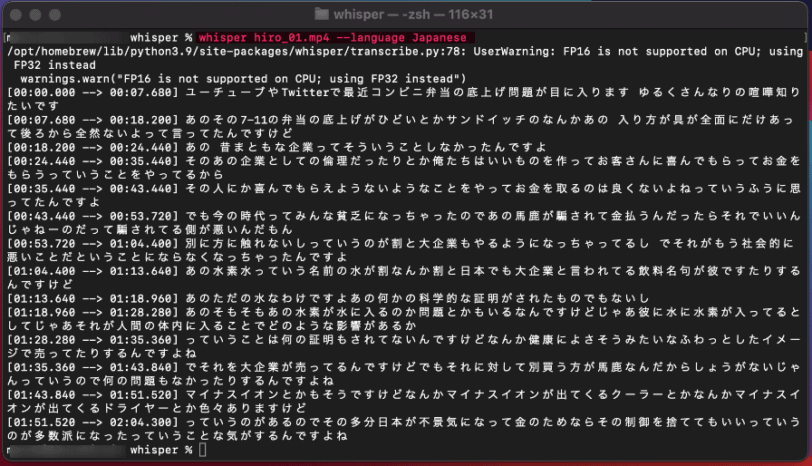
whisper 動画名.mp4 --language Japaneseすると文字起しが始まりますので、終わるまで待ちましょう。
かなりの短時間で作業が完了しました。
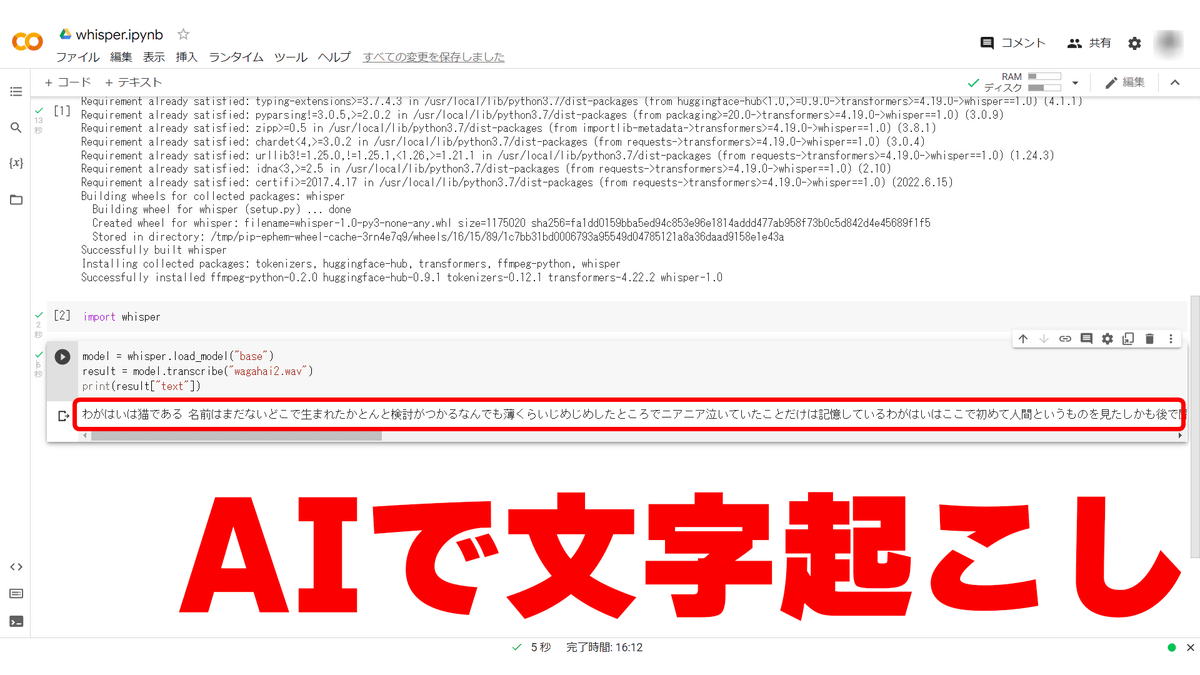
文字起しの結果の確認
フォルダに3つのファイルが生成されます。
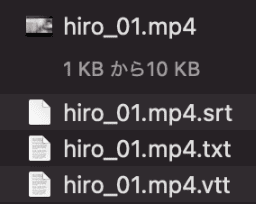
そのなかの.vttというファイルをテキストで開いた結果が以下になります。
日本語の精度は英語より劣るようですが、かなりのものです。
句読点がないのが読みずらいですが、セリフごとに仕分けしてくれるところが最高です。
追記:Whisperの精度をあげるために試した事
Whisperの精度を最大限まで高めるために試したことをメモしておきます。
コマンドで精度を最大まで上げる
--model large時間はかかりますが、このコマンドが一番Whisperの精度があがります。
whisper 動画名.mp4 --model large --language Japanese元素材をボイスだけ抽出する
Ultimate Vocal Removerというソフトでボイスだけ抽出します。
元素材の質によって大きく品質が変わるので、できるだけ良い設定にしましょう。
設定は下記の記事が参考になります。
この2つの仕込みをすれば、ほぼ完ぺきに文字起しができます。
Whisperで文字起しが困難になるケース
ただしWhisperでも2点だけ難しい点があります
- 人名や地名の場合、スペルが不安定な場合が多い
- 複数人の重なった音声は聞き取りをスル―される。
これだけは人力でチェックが必要になります。
とはいえ9割の完成したものが上がってくるので、本当に時短になります。
まとめ
本記事では話題のOpenAIによる文字起し「Whisper」を試してみました。
コマンドを叩くだけで、動画の文字起しがセリフごとに完了するのが素晴らしいですね。
この技術を使えば、例えば会議の議事録等でも使いやすいのではないでしょうか?
気になった方は是非試してみて下さい。