In this competition, you’re challenged to build a machine learning model that predicts which Tweets are about real disasters and which one’s aren’t.
この競争では、あなたは、どのツイートが本当の災害についてであるか、そして、どちらがそうであるか予測するモデルがそうでないということを知っているモデルを作るよう要求されます。
まずはファイルを読み込んでいます
train.csv
idとkeyWord,location,text 欠損値も多いです
5列あるものが7613行
4列あるものが3263行あります
| id | keyword | location | text | target |
| 1 | Our Deeds are the Reason of this #earthquake May ALLAH Forgive us all | 1 | ||
| 4 | Forest fire near La Ronge Sask. Canada | 1 | ||
| 5 | All residents asked to 'shelter in place' are being notified by officers. No other evacuation or shelter in place orders are expected | 1 | ||
| 6 | 13,000 people receive #wildfires evacuation orders in California | 1 | ||
| 7 | Just got sent this photo from Ruby #Alaska as smoke from #wildfires pours into a school | 1 | ||
| 8 | #RockyFire Update => California Hwy. 20 closed in both directions due to Lake County fire - #CAfire #wildfires |
1
|
test.csv
| id | keyword | location | text |
| 0 | Just happened a terrible car crash | ||
| 2 | Heard about #earthquake is different cities, stay safe everyone. | ||
| 3 | there is a forest fire at spot pond, geese are fleeing across the street, I cannot save them all | ||
| 9 | Apocalypse lighting. #Spokane #wildfires | ||
| 11 | Typhoon Soudelor kills 28 in China and Taiwan | ||
| 12 |
We're shaking...It's an earthquake
|
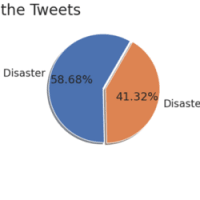
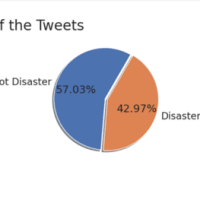
train.csvの一番右端にtargetという列があるのですが、まずはその数を比較してみます
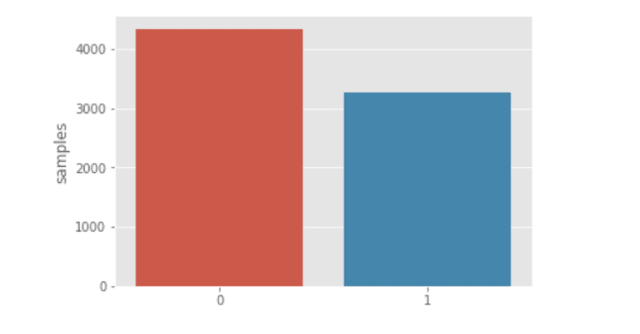
textの内容から考えるに、0が災害ツイートではない、1が災害ツイートであると考えられます
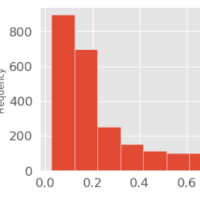
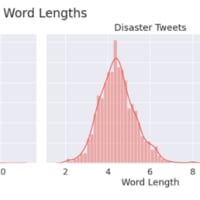
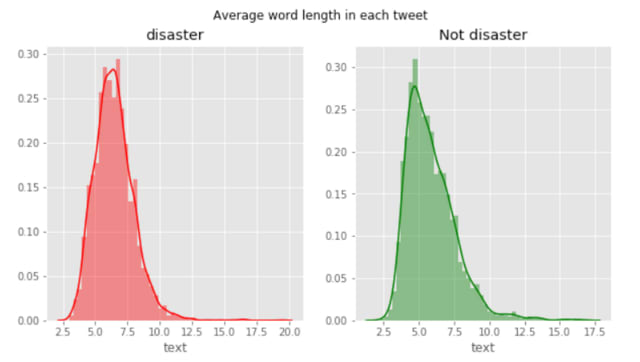
文字数から差がでるかどうか調べてみます
グラフ出力 左側が災害ツイート。右側が災害ツイートでない文字数分散となります
どちらも120文字にピークがあります。単純に文字数で差を出すのは難しそうです

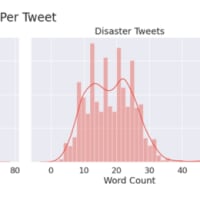
では単語数で比較をしてみたらどうでしょうか?
ツイートを単語ごとに分割し出力をしてみます
→1ツイートにいくつ単語が含まれているかどうか調べてみる
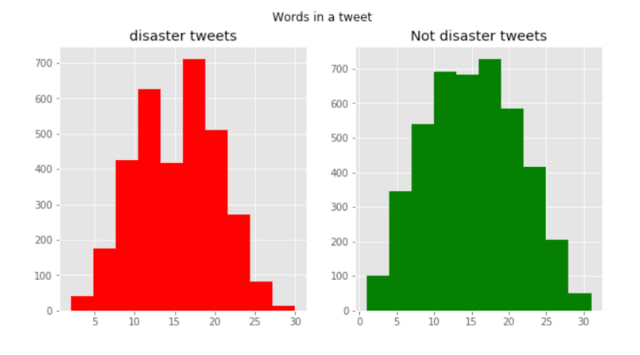
ツイートの平均単語数を調べてみます
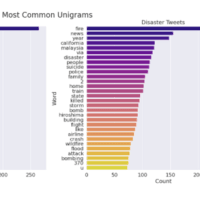
Tweetのストップワードについて、調べてみます
共通傾向としてはtheが多く、次は a , 非災害ツイートはin
非災害ツイート the,a, to,and ,of,in,you,is,for,my

災害ツイート the, in ,of ,a,to,and,on,for,is ,at
場所を特定するような単語 atが多いのは何となく分かります

次に句読点について解析をします
非災害ツイート

災害ツイート
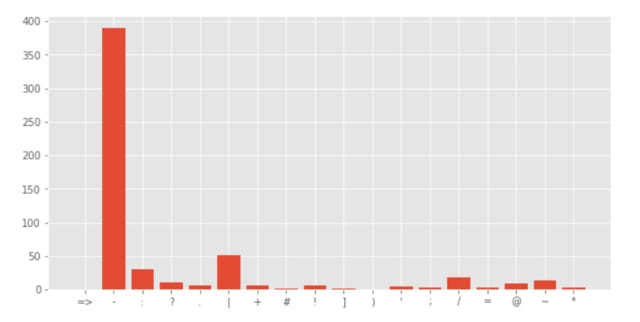
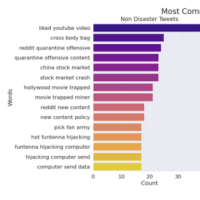
一般的な単語の傾向についても調べておきます
単語を整理する必要があることが分かります

単語の一般的なダイアグラムをチェックします
2単語ごとのつながりの数を計算します
クリーニングが必要です
訂正、句読点、除去HTMLタグと絵文字を取り出し削除します

つづりの修正をPythonの標準関数で行います
ベクトル化を行います
ここではコーパス・モデルを使います。
それは、3つの種類で利用できます:50D、100Dと200のDimentional。
我々は、100Dを使用します
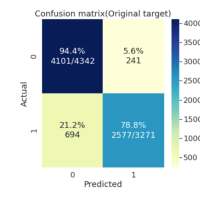
モデル化を行います